
Background
In examining the recent discourse on “Prompt Engineering,” we can observe a subtle yet important divergence.
On one hand, leading practitioners focused on building scalable systems (such as Andrej Karpathy) have actively advocated for the term “Context Engineering”, arguing that “Prompt Engineering” is insufficient to capture the complexity involved. In their view, prompt engineering is merely “coming up with a laughably pretentious name for typing in the chat box.” The real challenge in constructing agent systems lies not in writing prompts, but in designing the entire dataflow architecture that dynamically generates the final prompt.
On the other hand, recent academic and formal literature tends to use “Prompt Engineering” as a broad umbrella term, one that includes “supporting content” or “context,” grouping together all techniques for manipulating model inputs without changing model weights.
This terminological split reflects the maturation of the field. As AI applications evolve from simple, single-turn interactions to complex, stateful agent systems, the optimization of static instructions alone is no longer sufficient. The rise of “Context Engineering” marks an important distinction between two levels of activity:
- the skill of writing effective prompts, and
- the science of building automated systems that dynamically assemble and manage the information required for those prompts to succeed.
(In this article, we clarify that while “Prompt Engineering” may academically encompass context, in engineering practice, Context Engineering is a specialized discipline focused on how to dynamically construct and manage context.)
Redefining the Agent Dataflow: Context is All You Need
This section aims to establish the foundational concepts of Prompt Engineering and Context Engineering, and to clearly define their differences and connections. The shift from the former to the latter represents a key evolution in AI application development: from the industry’s early tactical focus on crafting instructions, toward a strategically driven architecture design shaped by the needs of scalable and reliable systems.
Prompt Engineering – The Art of Instructions
Prompt Engineering is the foundation of interaction with large language models (LLMs). Its core lies in carefully designing the input in order to guide the model to produce the desired output. This practice provides the baseline for understanding why Context Engineering is necessary.
Definition
A prompt is far more than a simple question; it is a structured input that may consist of multiple components. Together, these elements form the complete set of instructions through which we communicate with the model:
- Instructions: The core command to the model, explicitly stating the task to be performed.
- Primary Content/Input Data: The text or data that the model must process—the object of analysis, transformation, or generation.
- Examples/Shots: Demonstrations of desired input–output behavior, which serve as the basis for in-context learning.
- Cues/Output Indicators: Guiding words to trigger model output, or explicit requirements for output format (e.g., JSON, Markdown).
- Supporting Content/Context: Additional background information provided to help the model better understand the task scenario. It is precisely this component that represents the conceptual seed of Context Engineering.
Core Techniques of Prompt Engineering
Prompt engineers use a range of techniques to optimize model outputs, which can be categorized by complexity:
- Zero-Shot Prompting: Assigning a task directly to the model without providing any examples, relying entirely on the knowledge and reasoning it acquired during pretraining.
- Few-Shot Prompting: Including a small number (typically 1–5) of high-quality examples within the prompt to guide the model’s behavior. For complex tasks, this form of in-context learning has proven highly effective.
- Chain-of-Thought Prompting (CoT): Encouraging the model to decompose a complex problem into a sequence of intermediate reasoning steps, significantly improving performance on logic, mathematics, and reasoning tasks.
- Advanced Reasoning Techniques: Building on CoT, researchers have developed more sophisticated variants, such as Tree-of-Thought, Maieutic Prompting, and Least-to-Most Prompting, to explore more diverse solution pathways.
Limitations of a Prompt-Centric Approach
While Prompt Engineering is critical, it has inherent limitations when it comes to building robust, production-ready systems:
- Fragility & Non-reproducibility: Small wording changes in a prompt can lead to large differences in output, making the process resemble an art of trial-and-error rather than a reproducible science.
- Poor Scalability: Manually iterating and optimizing prompts does not scale effectively across large user bases, diverse use cases, or emerging edge cases.
- User Burden: This approach places the responsibility of crafting detailed, effective instructions entirely on the user, which is impractical for autonomous systems or those handling high-concurrency workloads.
- Statelessness: By design, Prompt Engineering is tailored to single-turn, “one-shot” interactions, making it ill-suited for long conversations or multi-step tasks that require memory and state management.
The Rise of Context Engineering: A Paradigm Shift
Context Engineering is not meant to replace Prompt Engineering, but rather to serve as a higher-order discipline with a stronger focus on system design.
Definition of Context Engineering
Context Engineering is the discipline of designing, building, and optimizing dynamic, automated systems that provide large language models with the right information and tools, at the right time, in the right format, so that they can reliably and scalably complete complex tasks.
If a prompt tells the model how to think, context provides the model with the knowledge and tools it needs to get the work done.
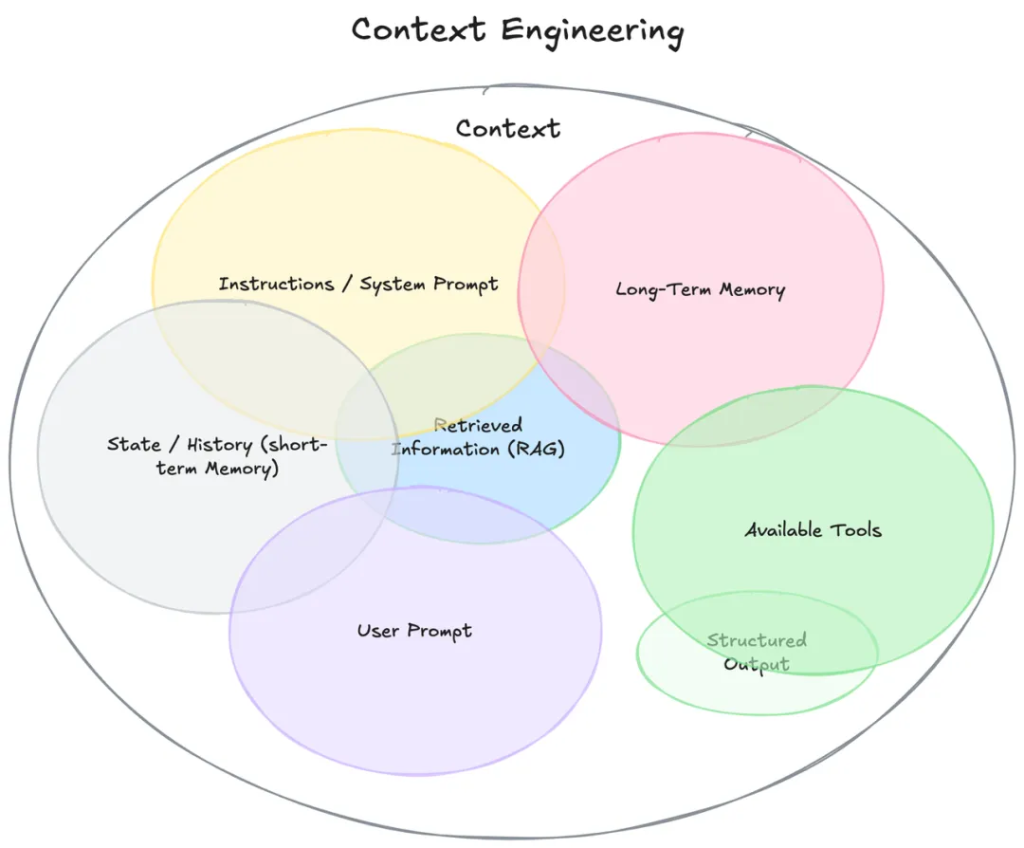
The Scope of “Context”
The definition of “context” has expanded far beyond a user’s single, immediate prompt. It now encompasses the entire ecosystem of information that an LLM can access before producing a response:
- System-level instructions and role definitions
- Dialogue history (short-term memory)
- Persistent user preferences and facts (long-term memory)
- Dynamically retrieved external data (e.g., via RAG)
- Available tools (APIs, functions) and their definitions
- Expected output formats (e.g., JSON Schema)
Comparative Analysis
Relationship: A superset, not a competitor
Prompt Engineering is a subset of Context Engineering.
- Context Engineering determines what content should fill the context window.
- Prompt Engineering focuses on optimizing the instructions within that window.
| Dimension | Prompt Engineering | Context Engineering |
| Primary Goal | Optimize instructions to elicit desired outputs from the model | Design systems to dynamically assemble and deliver the right context for reliable, scalable task completion |
| Core Action | Crafting and refining prompts (instructions, examples, cues) | Orchestrating dataflow: memory, retrieval, tool integration, role management |
| Scope | Single interaction or short session | Full information ecosystem: system prompts, history, memory, external data, tools, formats |
| Mode | Manual, trial-and-error, often artisanal | Automated, pipeline-driven, architectural |
| Scalability | Limited — brittle and hard to scale across users and edge cases | High — supports multi-turn, multi-agent, enterprise-scale systems |
| Required Tools | Prompt libraries, templates, prompt-tuning platforms | Orchestration frameworks, vector DBs, memory stores, workflow engines, tool registries |
| Debugging Methods | Prompt iteration, A/B testing, qualitative evaluation | System-level logging, context inspection, replay/reproducibility, automated eval suites |
Prompt Engineering vs. Context Engineering
Context Engineering Foundations: RAG
This section explains Retrieval-Augmented Generation (RAG) as the primary architectural pattern that enables Context Engineering. Moving from what it is to how it works, we detail the components and evolution of RAG systems.
Retrieval-Augmented Generation
Why is RAG not just a technique, but the architectural backbone of modern Context Engineering systems?
Addressing Core Weaknesses of LLMs
RAG directly resolves several inherent limitations of standard LLMs in enterprise use:
- Knowledge Freeze: An LLM’s knowledge is frozen at the cutoff of its training data. RAG injects real-time, up-to-date information at inference time.
- Lack of Proprietary Knowledge: Standard LLMs cannot access internal organizational data. RAG connects them to internal knowledge bases such as technical manuals, policy documents, etc.
- Hallucination: LLMs may fabricate facts. RAG anchors model responses to verifiable, retrieved evidence, increasing factual accuracy and credibility.
RAG Workflow
RAG typically operates in two stages:
- Indexing (Offline Phase): External knowledge sources are processed. Documents are loaded and chunked, then converted into vector embeddings by an embedding model. These vectors are stored in a vector database for retrieval.
- Inference (Online Phase): When a user submits a query:
- Retrieve: Convert the query into a vector and run a similarity search in the vector database to find the most relevant chunks.
- Augment: Combine the retrieved chunks with the original query, system instructions, etc., to construct a richer, enhanced prompt.
- Generate: Feed the augmented prompt into the LLM, which produces a reasoned, contextually grounded answer.
RAG Architecture Variants
- Naive RAG: The baseline implementation, suitable for simple Q&A but limited in retrieval quality and context handling.
- Advanced RAG: Improves quality with pre- and post-retrieval processing:
- Pre-retrieval: Better chunking strategies, query transformations (e.g., StepBack prompting).
- Post-retrieval: Re-ranking retrieved documents for higher relevance, and compressing context before passing it to the model.
- Modular RAG: A flexible, system-oriented view where components (search, retrieval, memory, routing) are interchangeable modules. Patterns include:
- Memory-augmented RAG: Incorporates conversation history for multi-turn interactions.
- Branching/Routing RAG: Uses a routing module to direct queries to the right data source or retriever.
- Corrective RAG (CRAG): Adds self-reflection; a lightweight evaluator scores retrieved documents and, if poor, triggers alternative retrieval strategies (e.g., web search).
- Self-RAG: Lets the LLM decide when and what to retrieve, triggering retrieval with special tokens.
- Agentic RAG: The most advanced form, embedding RAG into an agentic loop. The model can execute multi-step tasks, interact with multiple data sources and tools, and synthesize information over time.
The Role of Vector Databases
Vector databases underpin the retrieval step. They store, index, and serve embeddings at scale. Choosing the right solution requires balancing performance, scalability, and feature set.
The Context Stack: An Emerging Abstraction Layer
Looking at the components—data ingestion, chunking, embedding, vector DB, re-ranker, compressor, and finally the LLM—it becomes clear they form a coherent multi-layered architecture, which we can call the Context Stack.
The dataflow is straightforward:
- Offline indexing: Documents → chunking → embeddings → vector DB.
- Online inference: Query → embedding → vector search → re-ranking → compression → augmented prompt → LLM.
Vendors now specialize in layers of this stack:
- Database layer: Pinecone, Weaviate, Milvus.
- Application orchestration layer: LangChain, LlamaIndex.
- Re-ranking as a Service (RaaS): Cohere, Jina AI.
Understanding next-generation AI agent architectures means understanding Context Engineering—specifically, the Context Stack, its layers, and the trade-offs among components. This shifts the discussion from isolated techniques to system design and technology choices, which is far more valuable for engineers and architects.
Key Considerations in Selecting a Vector Database
Organizations must evaluate:
- Deployment Model: Fully managed cloud services (e.g., Pinecone) vs. self-hosted open-source (e.g., Milvus, Weaviate).
- Scalability: Ability to handle billions of vectors and high query throughput (e.g., Milvus).
- Feature Set: Support for hybrid search (keyword + vector), advanced metadata filtering, and multimodal data (e.g., Weaviate).
- Ease of Use & Flexibility: Simple APIs and minimal setup (Pinecone) vs. deep configuration options and multiple indexing algorithms (Milvus).
To provide a practical decision-making framework for technology selection, the table below compares several mainstream vector databases.
| Database | Key Differentiators | Ideal Use Cases | Scalability | Deployment Model | Indexing Algorithms |
| Pinecone | Fully managed, serverless, simple APIs, low latency | Teams needing fast implementation, zero maintenance, production-ready use | High, with cost scaling linearly | Managed cloud service | HNSW (default), supports customization |
| Weaviate | Built-in modularization, hybrid search, multimodal data support | Complex applications requiring keyword filtering, reasoning over complex data, etc. | High, supports distributed deployment | Open-source self-hosted / managed cloud service | HNSW |
| Milvus | Designed for large-scale workloads, supports multiple indexing engines, high performance | Enterprise-level apps requiring ultra-large-scale (billions of vectors) | Extremely high, with specialized scalability design | Open-source self-hosted / managed cloud service | HNSW, IVF, DiskANN, etc. |
| Qdrant | Strong payload filtering and vector+metadata retrieval, high memory efficiency | Scenarios requiring fine-grained filtering of complex data | Medium to high, supports sharding | Open-source self-hosted / managed cloud service | HNSW |
Comparative Analysis of Mainstream RAG Vector Databases
Core Concepts and Goals of Context Engineering
From Raw Data to Relevant Chunks
This section focuses on the initial stage of identifying and retrieving the most valuable information from a knowledge base.
Advanced Chunking Strategies
Text chunking is both the most critical and the most easily overlooked step in the RAG pipeline. Its goal is to create semantically coherent units of text.
- Problems with Naive Chunking: Fixed-size chunks are simple but often cut across sentences or paragraphs, leading to fragmented context and incomplete semantics.
- Content-Aware Chunking:
- Recursive Character Splitting: A smarter method that follows a hierarchy of delimiters (paragraph → sentence → word) to preserve natural structure as much as possible.
- Document-Specific Chunking: Uses the structure of the document itself—e.g., Markdown headers, functions in source code, or clauses in legal contracts.
- Linguistic Chunking: Uses NLP libraries (e.g., NLTK, spaCy) to split based on syntactic boundaries such as sentences, noun phrases, or verb phrases.
- Semantic Chunking: One of the most advanced strategies. It uses embedding models to detect semantic shifts in text and splits at those points, ensuring each chunk is highly cohesive in topic. Research shows this outperforms other methods.
- Agentic Chunking: A cutting-edge concept where an LLM agent decides how to chunk text—for example, decomposing it into a series of discrete propositions.
Improving Precision with Re-ranking
To balance retrieval speed and accuracy, industry practice commonly adopts a two-stage retrieval pipeline:
- Two-stage Process:
- Stage 1 (Recall): Use a fast, efficient retriever (e.g., bi-encoder vector search or lexical search like BM25) to cast a wide net and recall a large candidate set (e.g., top 100).
- Stage 2 (Re-ranking): Apply a more powerful but computationally expensive model to re-evaluate the smaller set, selecting only the most relevant documents (e.g., top 5).
- Cross-Encoder: Unlike bi-encoders that separately embed queries and documents before computing similarity, cross-encoders take both query and document as joint input. Through the attention mechanism, they capture subtle semantic relationships and produce more accurate relevance scores.
- Practical Impact: Re-ranking significantly improves the quality of the final context passed to the LLM, leading to more accurate answers with fewer hallucinations. In high-stakes fields such as finance and law, re-ranking is considered essential rather than optional.
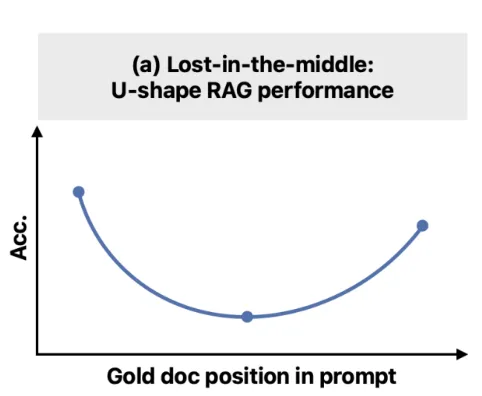
The Core Issue: Lost in the Middle
Lost in the Middle: How Language Models Use Long Contexts (arXiv:2307.03172)
Current LLMs face a fundamental cognitive limitation that makes naïve context-stuffing ineffective and has spurred the development of subsequent optimization techniques.
- Definition: LLMs show a distinctive U-shaped performance curve when processing long contexts. They leverage information well when it appears at the beginning (primacy effect) or end (recency effect) of the context window, but their performance drops sharply when key information is “hidden” in the middle.
- Experiment: In multi-document QA tasks, even when retrievers recall more relevant documents, model performance quickly plateaus. Simply increasing context length (adding more documents) does not help and can even harm performance as critical information gets buried.
- “Knows but Cannot Say”: The issue is not that the model fails to find the information. Probing its internal representations shows it often encodes the key information correctly but fails to effectively use it when generating answers. This suggests a disconnect between information retrieval and information utilization (or communication) within the model.
Balancing Context Richness and Window Limitations
At the heart of Context Engineering lies a fundamental tension. On one hand, providing rich and comprehensive context is essential for high-quality responses. On the other hand, the LLM’s context window is limited—and due to issues such as Lost in the Middle and contextual distraction, excessively long contexts can actually degrade performance.
A naïve approach might be to stuff as much relevant information as possible into the context window. Yet research and practice show this is counterproductive: the LLM becomes overwhelmed by irrelevant information, distracted, or simply ignores content that does not appear at the beginning or end of the window.
This creates a core optimization challenge: within a fixed token budget, how can we maximize “signal” (truly relevant information) while minimizing “noise” (irrelevant or distracting content), while also accounting for the model’s cognitive biases?
This consideration is the main driver of innovation in Context Engineering. All advanced techniques—semantic chunking, re-ranking, and later, compression, summarization, and agent isolation—are designed to manage this tradeoff effectively. Context Engineering is therefore not only about providing context, but about curating and shaping context to make it most effective for a cognitively limited processing unit (the LLM).
Optimizing the Context Window: Compression and Summarization
Goal of Context Compression
To shorten retrieved document lists and/or simplify individual document content, passing only the most relevant information to the LLM. This reduces API costs, decreases latency, and mitigates Lost in the Middle.
Compression Methods
- Filtering-based Compression
- LLMChainFilter: Uses an LLM to make binary yes/no judgments on each document’s relevance.
- EmbeddingsFilter: A faster, more economical method that filters documents based on cosine similarity between document and query embeddings.
- Content-extraction Compression
- LLMChainExtractor: Iterates through each document and extracts only the sentences or statements directly relevant to the query.
- Top-N Replacement as Compression
- LLMListwiseRerank: Uses an LLM to re-rank retrieved documents and return only the top N, serving as a high-quality filtering strategy.
Summarization as a Compression Strategy
For very long documents or extended dialogue histories, an LLM can generate summaries. These summaries are then injected into the context, preserving key information while significantly reducing token usage. This is a key technique for managing context in long-running agent systems.
Context Management in Agent Systems
From HITL to SITL
Prompt Engineering is fundamentally manual—a Human-in-the-Loop trial-and-error process. In contrast, Context Engineering, especially in its agentic form, is about building an automated System-in-the-Loop that prepares context before the LLM sees a prompt.
A human prompt engineer manually gathers information, organizes language, and tests prompts. A Context-Engineered system automates this:
- The RAG pipeline automatically gathers information.
- A router decides which information to collect.
- Memory modules persist and retrieve historical information.
This automation makes systems agentic—capable of autonomous, multi-step reasoning without humans micro-managing context at each step. The goal of Context Engineering is therefore to construct a reliable, repeatable context-assembly machine. This machine replaces the ad-hoc labor of prompt engineers, making true autonomy and scalability possible. The focus shifts from the craft of individual prompts to the system engineering that generates them.
Frameworks for Agent Context Management
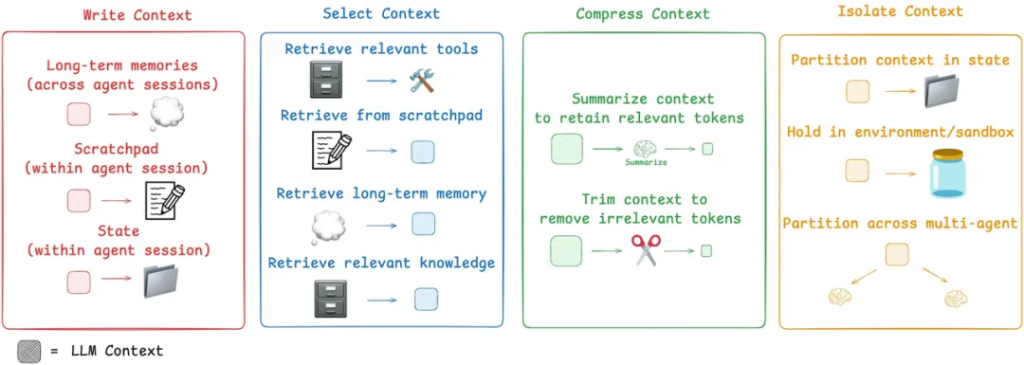
LangChain identifies four key strategies:
- Write – Persist Context
- Scratchpads: Temporary, in-session memory for recording intermediate steps in complex tasks.
- Memory: Long-term, persistent storage of key facts, user preferences, or conversation summaries, accessible across sessions.
- Select – Retrieve Context
- Dynamically select relevant context for a sub-task using RAG, from memory, tool libraries, or knowledge bases.
- This can even include applying RAG to tool descriptions themselves, to avoid overwhelming the agent with irrelevant tool options.
- Compress – Optimize Context
- Use summarization or pruning techniques to manage ever-growing context in long tasks, preventing window overflow and mitigating Lost in the Middle.
- Isolate – Partition Context
- Multi-agent systems: Decompose a complex problem and delegate sub-tasks to specialized sub-agents, each with its own focused context window.
- Sandbox environments: Execute tool calls in an isolated space and return only the necessary results to the LLM, keeping large, token-heavy objects outside the main context window.
Context Dataflow and Workflow Orchestration in Multi-Agent Architectures
LLMs are evolving from being passive responders to user queries into autonomous executors—capable of planning, decision-making, and performing multi-step complex tasks. These are what we now call AI Agents.
When an agent is no longer a simple input–output system, but instead must call tools, access databases, and engage in multi-turn interactions with users, a fundamental question arises: How is data flowing and managed inside the agent, and how should we approach technology choices?
Workflow vs. Agent
Before diving into technical details, it is crucial to establish a clear conceptual framework. The industry (e.g., Anthropic) tends to distinguish “agent systems” along two architectural dimensions:
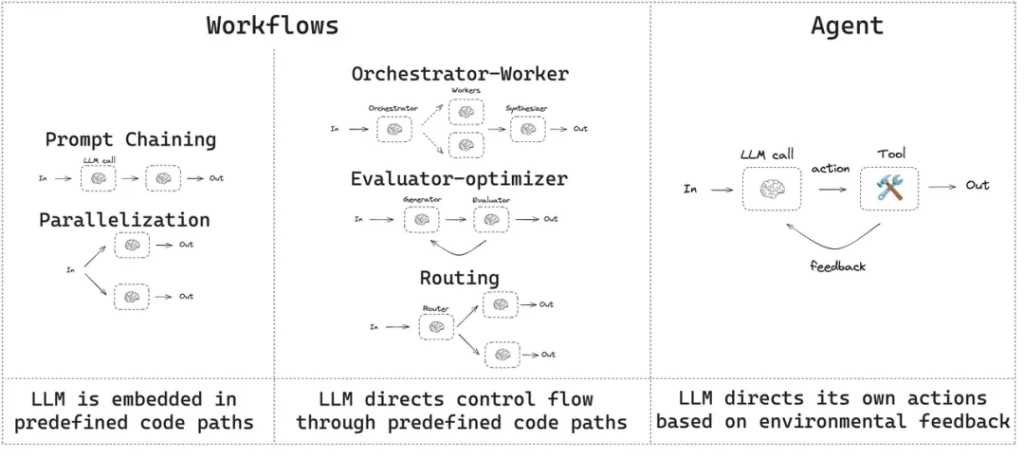
Workflows vs. Agents
- Workflows
Workflows are systems where LLMs and tools are orchestrated through predefined code paths. In this mode, the dataflow is fixed and explicitly designed by developers—similar to the expert systems popular in the last century.
For example:- Analyze the user’s email
- Based on the analysis, check the calendar for free time slots
- Draft a meeting invitation email
This mode is highly deterministic, easy to debug and control, and well-suited for scenarios with clearly defined business processes (e.g., high compliance requirements, sensitive data, or strict security standards).
- Agents
Agents are systems where the LLM dynamically guides its own process and tool usage, autonomously deciding how to complete tasks. In this mode, the dataflow is not pre-fixed, but determined by the LLM step by step according to the current situation and goal.
This mode offers high flexibility and is capable of handling open-ended problems, but it comes with reduced controllability and predictability.
In practice, complex agents are often hybrids—following a predefined workflow at the macro level, while granting the LLM autonomy at specific nodes. The core of managing this interplay is what we call the Orchestration Layer.
Core Architectures for Multi-Agent Orchestration: Implementing Predefined Dataflows
To enable reliable and controllable dataflows, developers have explored several mature architectural patterns. These can be used individually or combined into more complex systems.
Chained Workflows (Prompt Chaining) — Typical of the GPT-3.5 era
- Dataflow:
Input → Module A → Output A → Module B → Output B → … → Final Output - Principle:
Each module (LLM call) is responsible for one clearly defined sub-task.
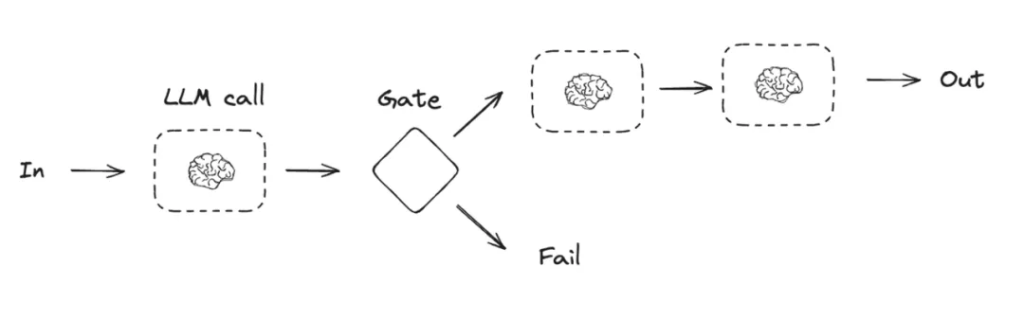
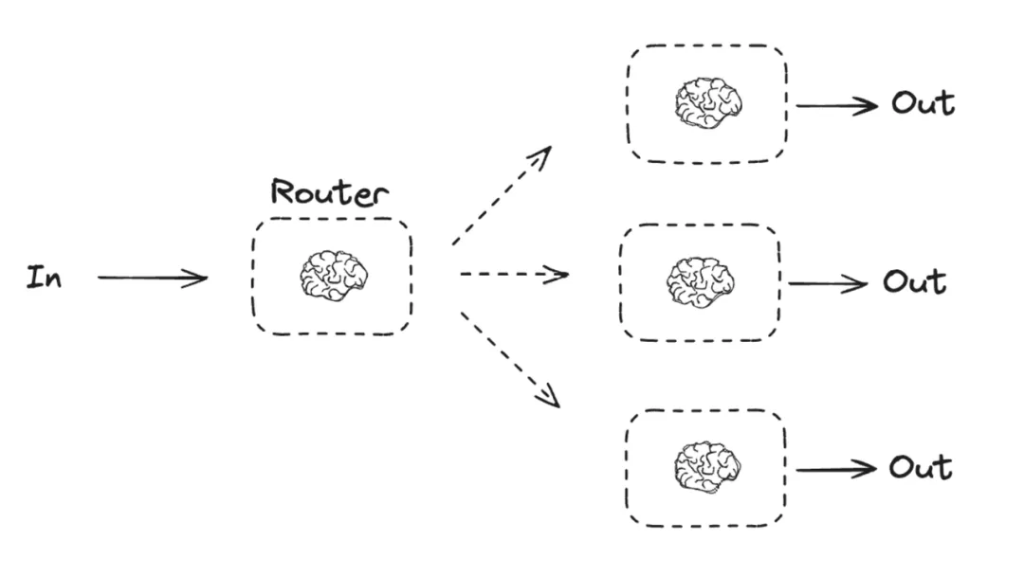
Routing Workflows (o3’s early working principle)
- Dataflow: Input → router selects → Output
- How it works: An LLM call acts as a router whose sole job is decision-making. It analyzes the input and emits an instruction telling the orchestration system which specific business module to invoke next.
- Implementation: In LangGraph, this logic is realized with Conditional Edges, where the output of one node determines the next hop in the graph.
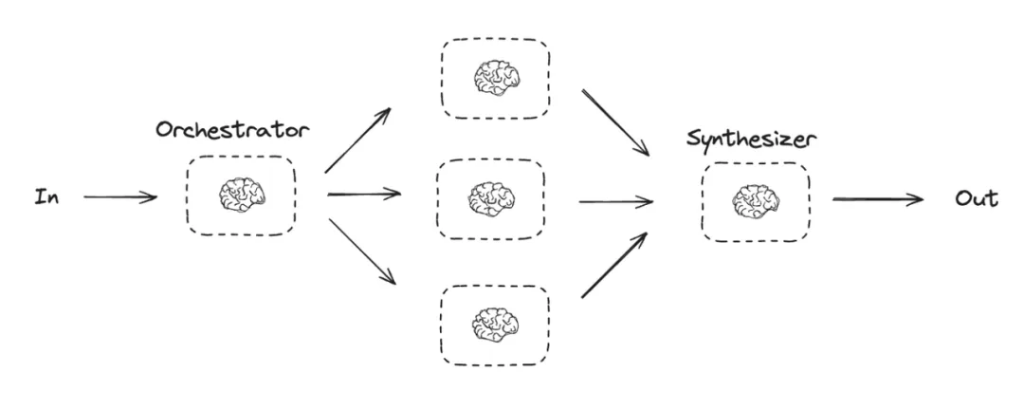
Orchestrator–Workers Pattern
- Use Case: For extremely complex tasks, a multi-agent architecture—also called the Orchestrator–Workers pattern—can be employed. A central Orchestrator agent is responsible for decomposing the main task and assigning sub-tasks to multiple specialized Worker agents.
- Dataflow: A hierarchical, collaborative flow:
Main Task → Orchestrator → Worker Agents → Results Aggregation → Final Output - How it works: Each Worker agent has its own independent context and dedicated tools, focusing on solving problems within a specific domain.
Decision & Data-Selection Mechanisms
In the architectures above, how does an agent (or its module) decide what data it needs and what to do next? This relies on its internal planning and reasoning capabilities.
ReAct Framework
ReAct (Reasoning + Acting) is a foundational and powerful framework that enables an LLM to dynamically determine data needs by emulating a human-like loop of reason → act → observe.
- Core Loop:
- Thought (Reasoning): The model outlines its current hypothesis or plan.
- Action: The model selects and calls a tool (e.g., search, DB query, API).
- Observation: The system records the tool’s result and returns it to the model.
- Iteration / Stop: The model decides whether to continue with another Thought→Action or to produce a final answer.
- What it solves:
- Converts open-ended problems into stepwise decisions.
- Lets the agent ask for data only when needed (on-demand retrieval).
- Creates an explicit audit trail (Thought/Action/Observation) that is easier to debug.
- Design Elements:
- Scratchpad / Memory: A running log of Thoughts, Actions, and Observations to keep state.
- Tool Registry: Structured, schema-validated functions the model can call.
- Policies & Budgets: Max steps, timeouts, and guardrails to prevent infinite loops.
- Answerability Check: If available evidence is insufficient, the agent can abstain or request more data.
- Minimal Prompt Skeleton (illustrative):
- System: “You are an agent that solves tasks using tools. Follow the Thought→Action→Observation format. Stop when you have enough evidence.”
- Tools: JSON schemas with names, arguments, and constraints.
- Stop Criteria: “If confidence is low or evidence is missing, ask for retrieval; otherwise output the final answer in the required format.”
- Example Flow (condensed):
- Thought: “I need the latest order status.”
- Action: get_order(order_id=…)
- Observation: {status: “backordered”, eta: “2025-10-03”}
- Thought: “Notify customer + create replenishment task.”
- Actions: notify_customer(…), create_replenishment(…)
- Final Answer: Summarize actions and ETA.
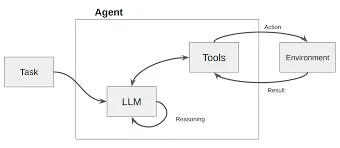
At its core, there is a loop:
- Thought: The LLM first performs internal reasoning. It analyzes the current task and available information, determines whether it lacks knowledge needed to complete the task, and formulates a next action.
Example: “The user asked about today’s weather in San Francisco, but I don’t know. I need to call a weather lookup tool.” - Action: The LLM decides to invoke a specific tool and generates the parameters required for that call.
Example: Action: search_weather(location=”San Francisco”). - Observation: The system executes the action (calls the external API) and returns the result to the LLM as observation data.
Example: Observation: “San Francisco is sunny today, 22°C.” - Thought again: Upon receiving the new observation, the LLM re-enters the reasoning step to decide whether the task is complete or further action is needed.
Example: “I now have the weather information and can answer the user’s question.”
In this loop, the dataflow is generated dynamically based on the LLM’s “Thought.” When the LLM determines external data is needed, it proactively triggers an Action to obtain it, then integrates the returned Observation into its context for the next decision.
Planning and Task Decomposition
For more complex tasks, an agent typically performs planning first. A higher-level planning module decomposes the user’s overarching goal into a series of smaller, concrete, executable subtasks.
- Dataflow: The planning module outputs a planning list that specifies the order of subsequent module invocations and their data dependencies.
(Recently popular “Claude Code,” the newly updated Cursor v1.2, and earlier Gemini/GPT “DeepResearch” exemplify this architecture.)
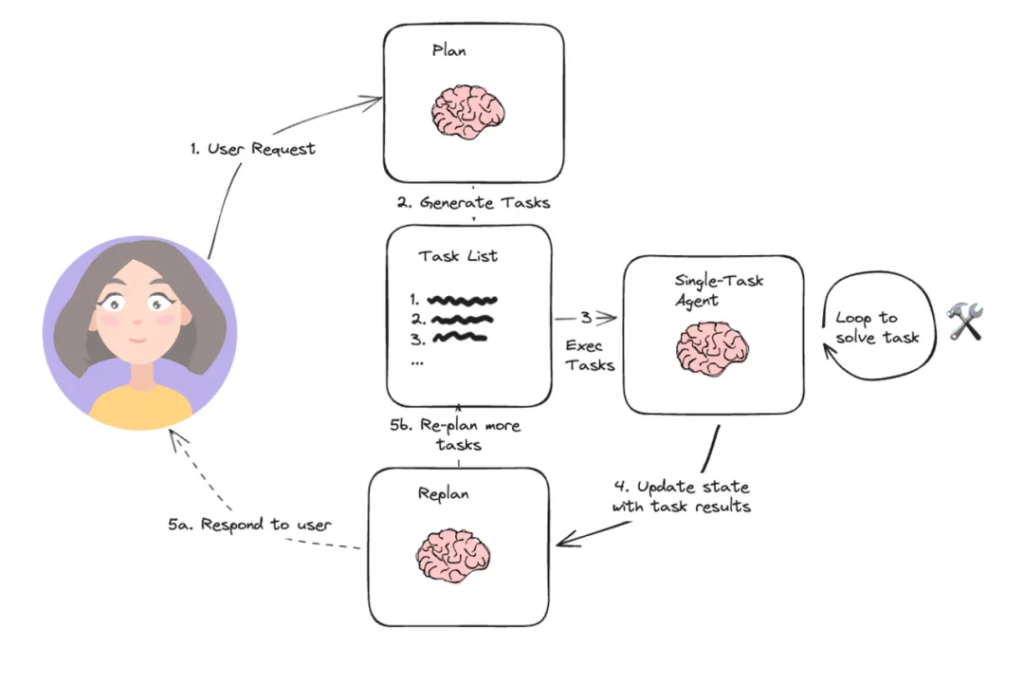
For a request like “Plan a five-day trip to Paris for three people,” the planning module might produce the following plan and define the required inputs/outputs for each step:
- [Collect user budget and preferences] → [Search round-trip flights]
- [Flight information] → [Search hotels based on travel dates and budget]
- [Hotel information] → [Plan the day-by-day itinerary]
- [Flights, hotels, and itinerary information] → [Generate the final itinerary and budget report]
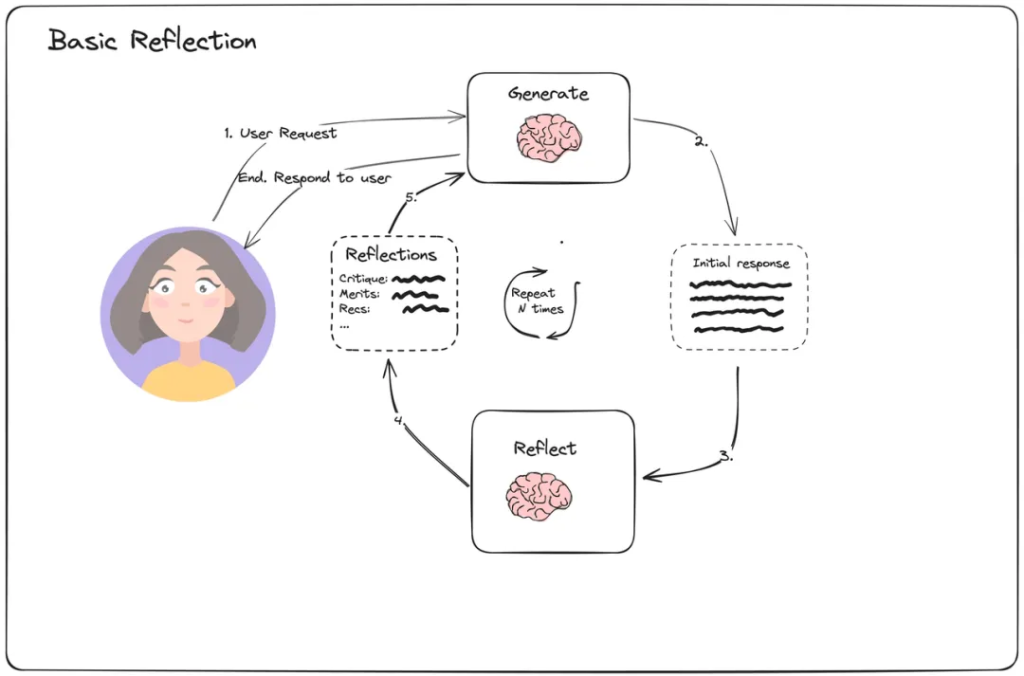
Reflection Mechanism
Advanced agent architectures also include a reflection mechanism. After executing an action or completing a subtask, the agent evaluates the quality and correctness of the result. If it detects issues, it can self-correct and re-plan its path. (As of this writing, this is the core technical approach used by major deep-research platforms.)
Dataflow: This forms a feedback loop. A module’s output flows not only to the next task module, but also to an evaluator module. The evaluator’s output (e.g., “success,” “failure,” “insufficient information”) then feeds back into the planning module, which adjusts subsequent dataflows accordingly.
Frameworks and Tools
The architectures and mechanisms described above don’t exist in a vacuum—they are realized through concrete development frameworks. As an extension of LangChain, LangGraph provides a powerful toolkit for building agent systems with explicit dataflows.
LangGraph: Defining Workflows with Graphs
The core idea of LangGraph is to build agent applications as a state graph composed of nodes and edges, making the flow of data between modules explicit.
- State: The heart of the graph—a central data object shared by all nodes. Think of it as a data bus or shared memory. Developers predefine the State schema; each node can read and update this State during execution.
- Nodes: Computational units or steps in the workflow. A node is typically a Python function that takes the current State as input, performs a specific task (e.g., calling an LLM, executing a tool, processing data), and returns updates to the State.
- Edges: Connections between nodes that define the workflow path—i.e., which node the data should flow to after the State is updated.
- Simple Edges: Fixed, unconditional transitions used to implement chained workflows.
- Conditional Edges: Routing logic that selects the next node based on a function’s output, enabling branching flows.
- Checkpointer: A persistence mechanism that automatically saves the State after each step. This is essential for long-term memory, interruption and resumption, and Human-in-the-Loop processes.
For AI agents handling complex business processes, the core challenge has shifted from merely optimizing information retrieval (e.g., RAG) or prompts to the careful design and orchestration of internal workflows and dataflows.
The Future of Context Engineering
- Rise of Graph RAG. Standard vector-based RAG has limitations when dealing with highly interconnected data. Graph RAG, built on knowledge graphs, retrieves not only discrete information chunks but also their explicit relationships—enabling more complex multi-hop reasoning and more context-accurate answers.
- Greater agent autonomy. More autonomous systems such as Self-RAG and Agentic RAG will become mainstream, with LLMs taking on more responsibility for managing their own context. This will increasingly blur the boundary between Context Engineering systems and the LLM itself.
- Beyond fixed context windows. Active research on the Lost in the Middle problem explores new model architectures (e.g., improved positional encodings) and training techniques. Breakthroughs here could fundamentally loosen the constraints that Context Engineers face today.
- The ultimate goal. Context Engineering is a bridge—a sophisticated set of compensatory mechanisms that addresses the reality that LLMs don’t read minds—they read tokens. The long-term aim of AI research is to build models with stronger internal world models, reducing reliance on large external context scaffolds. The evolution of Context Engineering will be a key indicator of progress toward that goal.
Reference:
- www.microsoftpressstore.com, https://www.microsoftpressstore.com/articles/article.aspx?p=3192408&seqNum=2#:~:text=Prompt%20engineering%20involves%20understanding%20the,as%20additional%20context%20or%20knowledge).
- Core prompt learning techniques | Microsoft Press Store, https://www.microsoftpressstore.com/articles/article.aspx?p=3192408&seqNum=2
- Prompt Engineering for AI Guide | Google Cloud, https://cloud.google.com/discover/what-is-prompt-engineering
- arXiv:2402.07927v2 [cs.AI] 16 Mar 2025, https://arxiv.org/pdf/2402.07927
- What is Prompt Engineering? – AI Prompt Engineering Explained – AWS, https://aws.amazon.com/what-is/prompt-engineering/
- Which Prompting Technique Should I Use? An Empirical Investigation of Prompting Techniques for Software Engineering Tasks – arXiv, https://arxiv.org/html/2506.05614v1
- The rise of “context engineering” – LangChain Blog, https://blog.langchain.com/the-rise-of-context-engineering/
- Context Engineering – LangChain Blog, https://blog.langchain.com/context-engineering-for-agents/
- A Systematic Survey of Prompt Engineering in Large Language Models: Techniques and Applications – arXiv, https://arxiv.org/html/2402.07927v2
- Unleashing the potential of prompt engineering for large language models – PMC, https://pmc.ncbi.nlm.nih.gov/articles/PMC12191768/
- Retrieval Augmented Generation (RAG) for LLMs – Prompt Engineering Guide, https://www.promptingguide.ai/research/rag
- What Is Retrieval-Augmented Generation aka RAG – NVIDIA Blog, https://blogs.nvidia.com/blog/what-is-retrieval-augmented-generation/
- Never Lost in the Middle: Mastering Long-Context Question Answering with Position-Agnostic Decompositional Training – arXiv, https://arxiv.org/html/2311.09198v2
- Mastering Chunking Strategies for RAG: Best Practices & Code Examples – Databricks Community, https://community.databricks.com/t5/technical-blog/the-ultimate-guide-to-chunking-strategies-for-rag-applications/ba-p/113089
- How to do retrieval with contextual compression – Python LangChain, https://python.langchain.com/docs/how_to/contextual_compression/
- How do I choose between Pinecone, Weaviate, Milvus, and other vector databases?, https://milvus.io/ai-quick-reference/how-do-i-choose-between-pinecone-weaviate-milvus-and-other-vector-databases
- Retrieve & Re-Rank — Sentence Transformers documentation, https://www.sbert.net/examples/sentence_transformer/applications/retrieve_rerank/README.html
- arXiv:2406.14673v2 [cs.CL] 4 Oct 2024, https://arxiv.org/pdf/2406.14673?
- Lost in the Middle: How Language Models Use Long Contexts – Stanford Computer Science, https://cs.stanford.edu/~nfliu/papers/lost-in-the-middle.arxiv2023.pdf
- LLMs Get Lost In Multi-Turn Conversation – arXiv, https://arxiv.org/pdf/2505.06120
- How to do retrieval with contextual compression – LangChain.js, https://js.langchain.com/docs/how_to/contextual_compression/
- Building Effective AI Agents \ Anthropic, https://www.anthropic.com/research/building-effective-agents
- What is LLM Orchestration? – IBM, https://www.ibm.com/think/topics/llm-orchestration
- Agent architectures, https://langchain-ai.github.io/langgraph/concepts/agentic_concepts/
- What is a ReAct Agent? | IBM, https://www.ibm.com/think/topics/react-agent
- LLM Agents – Prompt Engineering Guide, https://www.promptingguide.ai/research/llm-agents